
What’s the difference between misattribution vs. managed attribution? We look at the levels of control each type of attribution provides online investigators.
The average internet user spends more than six hours online every day visiting countless websites — each collecting an abundance of identifying information creating a unique digital fingerprint specific to the user.
The internet is built to track users so websites can display personalized content like advertisements and customize browsing experiences. Legacy browsers such as Chrome, Firefox or Safari allow websites to obtain this personal, identifying information. For most people this isn’t a big deal, but for online investigators, it’s a critical problem.
The same tracking mechanisms which enable personalized ad experiences and other mundane functions can be exploited by adversaries and investigative targets. Combined, the bits of collected information can give away investigators’ identity or intent. Once adversaries know who you are and what you’re up to, they can disappear, disinform or retaliate against you or your organization — in cyberspace or the real world. Having a system to control your online presence and attribution can solve this problem. But as we’ll see, not all systems are created equally.
Listen to NeedlStack’s Hidden dangers of the digital fingerprint podcast episode for more information on better protecting yourself and your organizations.
Defining Attribution
First, let’s define what attribution is and why it’s important to your online presence. Attribution refers to all the identifiable details that websites collect each time you visit. These details are passed to websites via different sources and include:
- Internet address and connection: registered owner, subscriber information
- Browser and device type: OS, software/plugins installed, time zone, audio/video devices, cookies, HTML5 local storage, HMTL5 canvas fingerprinting, audio rendering
- Unique online behavior: social media connections, shopping interests, websites visited, account activity
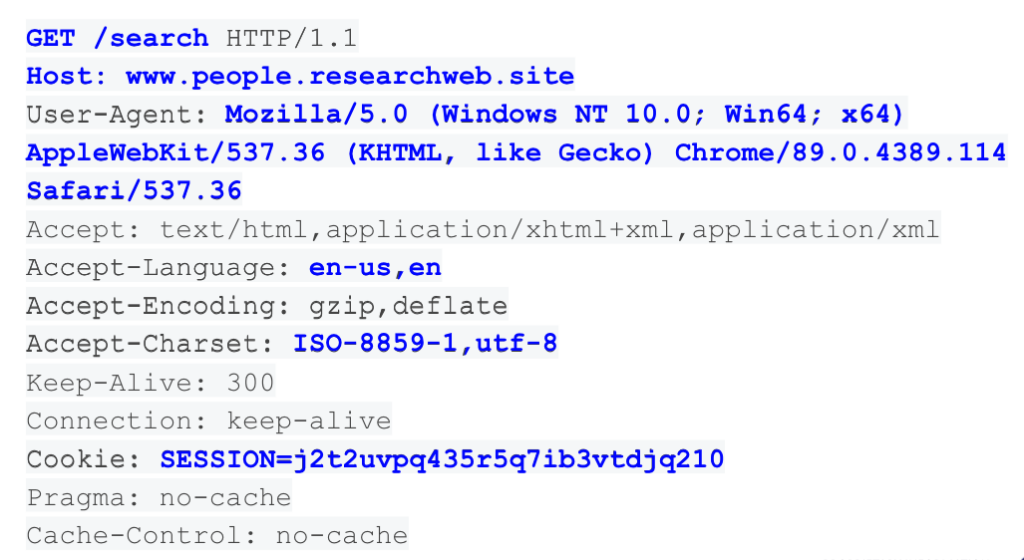
The above screenshot shows an example of information disclosed when you request a website. This information ensures compatibility with the content that will be displayed; for example, if you’re requesting from a mobile device, the website will display differently than on a desktop, or the language of the displayed content will match the language setting of your device.
Separately, these components may be insignificant, but all together they can help websites — and their webmasters — track and identify who you are, who you’re working for and what your interest is in a certain site.
Misattribution vs. Managed Attribution
So how are online investigators supposed to protect their identity and organization from data-collecting websites and the subjects they’re investigating? There are three approaches to this problem: non-attribution, misattribution and managed attribution. These can be products, services or DIY, in-house systems like “dirty” connections to the internet.
Let’s look at how each approach works and how each suits online investigators’ core needs of:
- Blending in with the crowd so as to not arouse suspicion in their investigations’ subjects, which could put the investigation at risk
- Maintaining security to avoid infection via malicious content (malware), which can be encountered by accident or in retaliation/targeting by adversaries
Non-Attribution
Non-attribution describes a solution where no data can be tracked and activity cannot be linked to a specific person or entity. Non-attributable systems are often composed of separate, standalone, internet connections or networks. In short, these systems aim to let individuals browse the internet completely anonymously. While this might sound ideal, it is not only counterproductive to the aim of blending in with the crowd, it’s virtually impossible to maintain.
In terms of tradecraft, being completely anonymous can arouse suspicion, making it obvious you have something to hide. And over time, some degree of attribution begins to accumulate from browsing activity and behavior, eroding the effectiveness of the non-attribution approach.
Misattribution
Misattribution is essentially pretending to be someone else online. Through misattribution systems, users are able to put out false information in order to mislead others. This can mean changing or misrepresenting one’s network address, browser related attributes or saved data. While there are many ways to achieve misattribution, incognito modes and VPNs are the most common. These systems provide an imperfect and false sense of misattribution as data is still associated with your organization. VPNs, for example, still attribute browsing through behaviors and history and only partially obfuscate attribution for limited times. What’s more, they don’t prevent malware infection, leaving investigators and their organizations exposed to cyber risks.
Learn more: What VPNs and Incognito Mode still give away in your online identity >
Managed Attribution
A subset of misattribution, managed attribution allows users to easily manage and customize their attribution and online presence. Depending on what type of research or investigation you want to conduct, managed attribution grants you the power to control specific aspects of your online identity. These aspects can include your browser fingerprint (time zone, language, keyboard, OS, device type, web browser) and network address (physical location, ISP, subscriber information). Managed attribution also gives users the ability to initiate isolated sessions without persistent tracking mechanisms.
Learn more: What is managed attribution and how does it improve online investigations? >
Managed Attribution as a Service: Purpose-Built for Online Investigators
For those conducting online investigations, managed attribution is the best system to protect their identity and objectives. This solution as a service (for example, Silo for Research), grants users the ability to use their own, everyday computers, but browse the web via a separate, cloud-based service. Managed attribution as a service also allows users to select their physical location via egress node/network; it also allows them to isolate their browsing session from their actual workstation to prevent malware infection or identification by websites. As many investigations require chain of custody or other auditability requirements, managed attribution services can also provide a full audit trail of online investigation activity.
Through customization and cloaking appearances to external parties, online investigators can complete their investigations safely and thoroughly.
If you’re interested in using a managed attribution service, request a demo of Silo for Research which enables managed attribution in online investigations for:
- Intelligence and evidence gathering in law enforcement
- Trust and safety
- Fraud and brand misuse
- Security intelligence
- Financial crime and compliance
- Corporate research and protection


