
The Collection #1 loot archive of stolen credentials is only the tip of the archive. All 5 collections contain more than 1TB of raw credential data awaiting download by attackers.
Note: This blog post was originally published in February 2019 and reflects the cybersecurity landscape and data available at that time. It remains online as a historical reference and may not reflect current threats, tools, or best practices.
You’ve seen the headlines about a loot archive of stolen credentials called “Collection #1” that was leaked online in January 2019. This collection contains 772,904,991 entries, one of the most significant credential leaks yet. The credentials are all stored within an email:cleartext_password format, making credential stuffing attacks relatively easy without having to worry about deciphering hashes.
As worrisome for potential targets as this can be, this post doesn’t deal with this particular pile of data (read Troy Hunt’s analysis of “Collection #1” leak). Instead, I’ll take a closer look at why there’s a “#1” next to the collection name. While #1 is a massive heap of data, it’s only the tip of the proverbial iceberg. There are five collection archives in total, containing a total of 1TB worth of raw credential data waiting to be downloaded by attackers. So what’s in Collections 2 – 5?
What about collections 2-5?
It’s worth examining these archives – plus a few bonus items from within the main repository – because of the enormous potential for exploit they represent. For attackers embarking on, say, an automated phishing attack, email login credentials are of tremendous value, given how many users manage all their bank, utility and shopping accounts from one account.
When data like this surfaces, automated attacks are likely to follow. They succeed, often with minimal effort, by exploiting the “weakest link” in target organizations. In late January, Basecamp faced a large scale credential stuffing attack. Dailymotion also faced a similar attack on the same day and was forced to reset all the passwords of suspected users. There’s a good chance the credentials used in both attacks came from this collection.
The archive that Troy Hunt has analyzed and placed inside haveibeenpwned.com is roughly 87.18 GB. Collection #1 contains 772,904,991 credentials. As it turns out, they represent only a small fraction of the entire data set.
To get an idea of how big the complete collection is, there is a total of 29,083,053,678 entries (calculated by using GNU wc utility). Keep in mind this number also includes any white spaces that might appear in the combo lists. Check out the breakout by email service providers:
Yahoo: 6,413,950,221 (yahoo.com, .ca, .fr, .co.uk, et al)
Hotmail: 4,130,645,551 (hotmail.com, .ca, .co.uk, .fr, et al)
Gmail: 2,980,903,393 (gmail.com)
AIM / AOL: 1,021,510,538 (aim.com | aol.com)
Yandex: 868,467,900 (yandex.com | yandex.ru)
Live: 590,784,654 (live.com, .fr, .co.uk, et al)
.edu: 117,493,160
Mail: 72,530,713 (mail.com | email.com)
Outlook: 37,770,997 (outlook.com)
Apple: 36,941,682 (icloud.com | mac.com)
.gov: 28,263,752
Protonmail: 66,848 (protonmail.com | protonmail.ch)
Almost 20 years’ worth of data breaches
These numbers were calculated using GNU grep and inserting email domains and TLDs. Note: more than six billion entries just for Yahoo (world population in January 2019: 7.7 billion). Am I wrong, or are we looking at the biggest leak of credentials to ever surface on the internet?
Let’s put this find in perspective. Much of this collection archive has been circulating in dark web forums for around three years, and the data within it (from thousands of data breaches) goes back even further, covering almost 20 years. Only recently has this data been released online by its previous buyers on RaidForums.
So where did the collection come from? Security researcher Brian Krebs believes a seller who goes by the name “Sanix” is behind these collection archives. Most of this data has been compiled from various underground marketplaces, escrows, and forums. Sanix was selling lifetime access to the collection for $45 in bitcoin or ethereum. That’s all it took for interested parties to have the entire collection at their disposal.

Sanix couldn’t have collected this entire archive of past data breaches alone. Inspecting some of the directories more closely, we come across aliases used by the people who did the actual collecting and dealing. Aliases credited in the depths of the collection are “ТЫ С4АСТЛNВ” (“You are 4astin”), “ALEEEK”, “Разбитая база” (“Broken base”), “сборка” (“assembly”), to name a few.
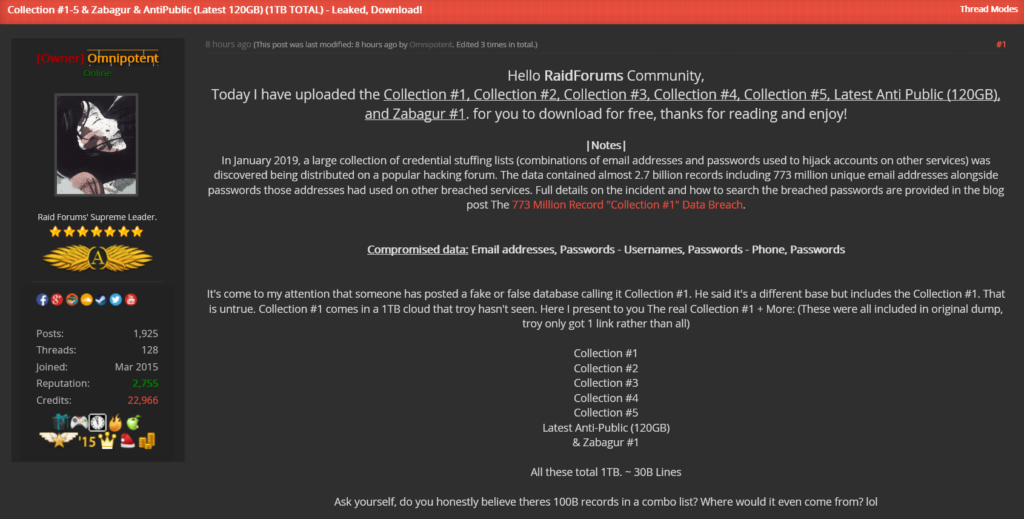
After the data was leaked, the original MEGA.nz cloud storage holding the data was taken down for violating MEGA’s terms. That didn’t stop users on RaidForums from re-uploading it as a bulletproof torrent for anyone to download.
Let’s take a closer look at the core of this massive archive. There are seven main directories in the collection, each of them are named as follows; “ANTIPUBLIC #1”, “AP MYR & ZABUGOR #2”, “Collection #1”, “Collection #2”, “Collection #3”, “Collection #4”, and “Collection #5”.
Valid and working? Check.
At first glance, I thought that “ANTIPUBLIC #1” was a reference to the original “anti-public” archive that was leaked in December 2016. The original archive was 16.8 GB, but this new one contained 85.1 GB of additional data. Anti-public is a tool used heavily in Russia to determine the legitimacy of credentials. It’s similar to another widely used tool called “SentryMBA”. It takes in raw credentials, verifies them by passing the data to numerous platforms like Twitter or Facebook and filters them into a separate list containing credentials that are valid and working.
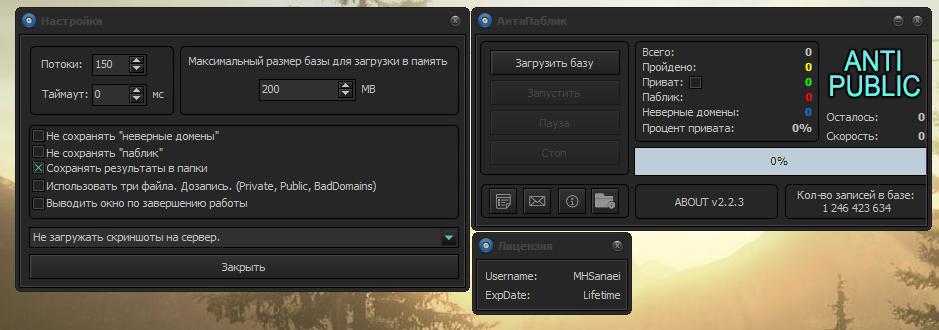
This practice is called credential stuffing. Data leaked from one service is used elsewhere for automated login campaigns on other services, based on the assumption that the victims have used the same email and password across numerous services.
Some tools used in such automated attacks evade login detection by using thousands of proxies to hide the fact that the login attempts are all originating from the same source. They also use evasion techniques, such as including random but common user agent strings per login request. This would make the traffic appear like it’s genuinely coming from different machines around the world.
What’s in a name?
What I found interesting is how each directory name gave me a small clue on the nature of the data, its author, and sometimes its origins. For instance, one sub-directory is called “AP MYR & ZABUGOR #2”, the AP stands for anti-public, and “Zabugor” means the emails within the list are not from Russian services.
Credential thieves often avoid attacking certain regional platforms to avoid drawing too much attention from local law enforcement. “MYR” is an acronym for mail.ru, yandex.ru, rambler.ru (similar to MYRQ which has qip.ru thrown into the mix). It’s essentially the opposite of Zabugor. This archive contains 19.4 GB worth of working email:pass data obtained from the anti-public tool separated into Zabugor and MYR sets.
Let’s skip Collection #1 since it’s been widely covered and dive straight into the remaining 4 main directories (Collection 2 – 5). Collection #2 is roughly 465 GB (that’s almost half of the entire archive). Within Collection #2 is another noteworthy directory called “New combo cloud”, and it contains 97 more directories all categorized by interest. Combo lists are arranged by whether the victim is into gaming, hacking or pornography. They also contain region-specific categories, for example Canada, US, UK, China and Japan.
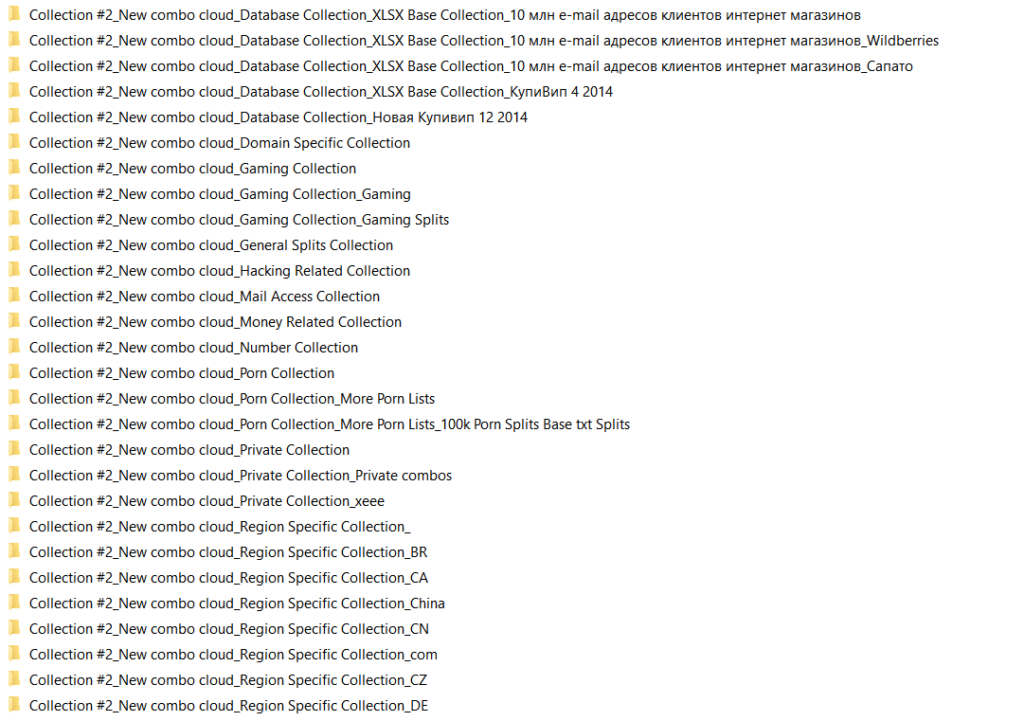
Whoever put this collection together spent significant effort on categorizing data this way, making credential stuffing attacks extremely easy for less knowledgeable or skilled attackers.
For instance, if someone wanted to obtain a bunch of stolen cryptocurrency assets, they would simply credential stuff cryptocurrency platforms and exchanges like Coinbase using the lists obtained from the “Money Related Collection” or “BTC combos” directory. The credentials within each directory are in plaintext as well. The attacker doesn’t even need to know how to “decipher” hashes.
How would they have categorized them? It all boils down to where the data came from. If the source database is from BTC-e.com (a cryptocurrency exchange that was seized by the U.S. government in July 2017), then the credentials would be strictly money oriented and to be used only to credential stuff exchanges, trading platforms, and the likes.
Collection #3 comes essentially in the same format and categorization, just with less data. Although it contains many credentials, it is better described as a tool arsenal. This collection contains several binaries, including “BonusBitcoin.co [B&C] by ALEEEK.exe.” The filename indicates that ALEEEK is its potential author, VirusTotal tells us that this binary has a detection rate of 26/68 and that it was created in 2017-08-09 03:17:17.
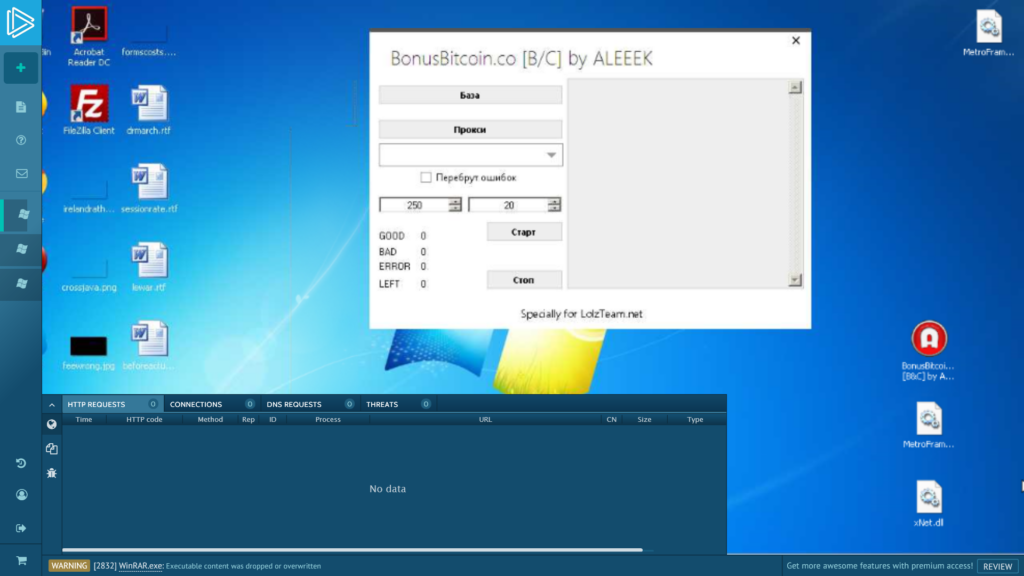
Further inspection reveals that this tool is used to credential stuff a bitcoin faucet located in BonusBitcoin.co to retrieve any bitcoin on every account. In other words, with this tool, an attacker can figure out the credential used on that site to then steal the satoshi (smallest bitcoin unit) stored on the account.
Another binary found in Collection #3, “FastChecker v 1.0.exe”, turns out to be a basic credential stuffing tool, similar to SentryMBA. Attackers can use it to verify email credentials using multiple SOCKS proxy connections (same evasion tactic we saw earlier).
Collection #4 contains mostly combo lists that had already been parsed and verified to be working – categorized combinations for bitcoin, gaming, etc., including credentials for a few less prominent online stores that handle data in an insecure fashion. The separation of Russian and American credentials, a familiar pattern, makes me think the whole cache is of Russian origin.
Lastly, Collection #5 also followed the same routine, only this time I saw a new focus on specific data like combos for specifically Social media platforms, money combo section, and a VIP combo section. VIP combo lists are usually private, unshared, valid and working sets of credentials, meaning they (should) work if you tried to log in with the given entries. This VIP list spans 12.4 GB of raw email:cleartext_pass files.
The terabyte takeaway
- We can expect more, even larger archives to surface, and should ensure our credentials used at one provider are useless for potential attackers at another.
- Dealers/traders of compromised data are becoming more resilient and efficient at what they’re doing, by proliferating automated tools, aggregating stolen and unintentionally leaked data. They are taking advantage of file-sharing platforms like MEGA that allow them to quickly transfer terabytes of data, as long as the links stay private and no one reports them.
- Attacks fueled by such data are aimed at finding the “weakest link” in the target organization with minimal effort, and they frequently succeed. Businesses should mandate the use of password managers and 2FA to prevent weak passwords and other risks of compromising credentials.
Spend some time and enforce secure password managers like KeePass or 1Password. You can also take advantage of U2F security keys for 2-factor authentication, such as the Yubikey from Yubico or the Titan security key from Google. And if you’re looking for a failsafe method for isolating the password manager from your machine and the entire browser session, consider Silo, the secure cloud browser.


